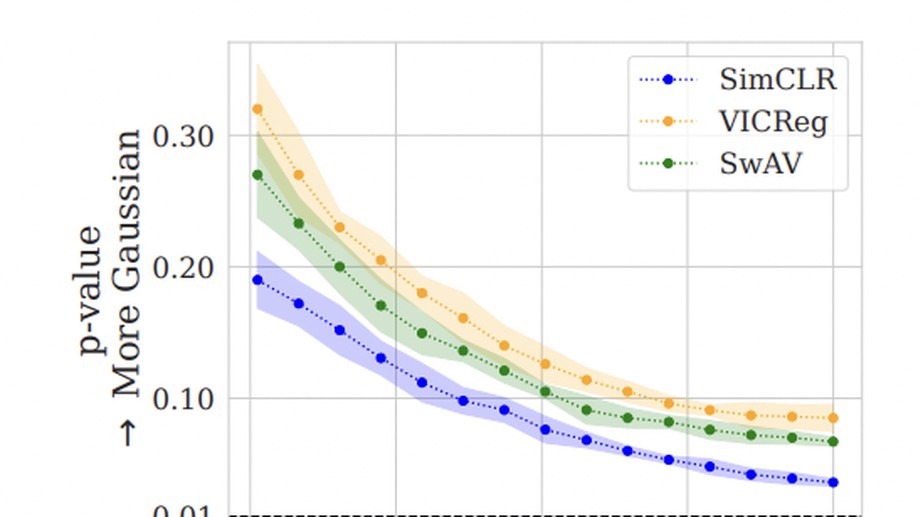
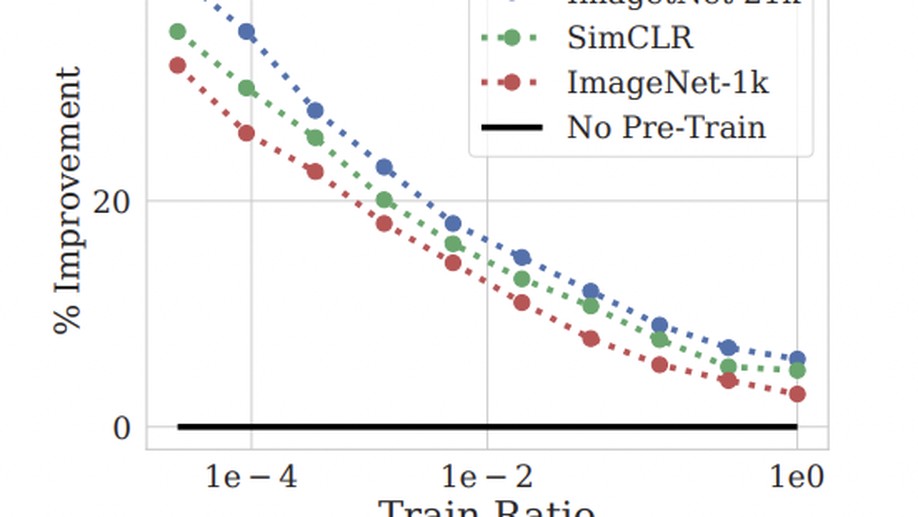
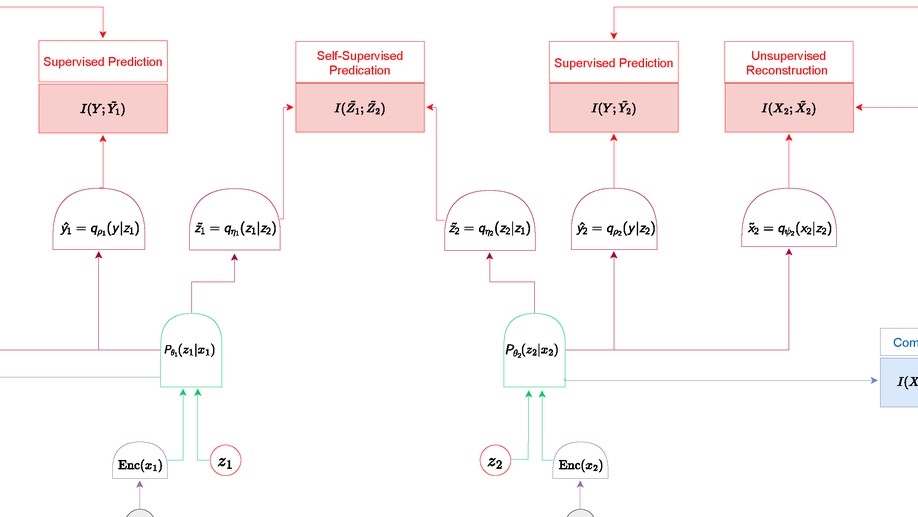
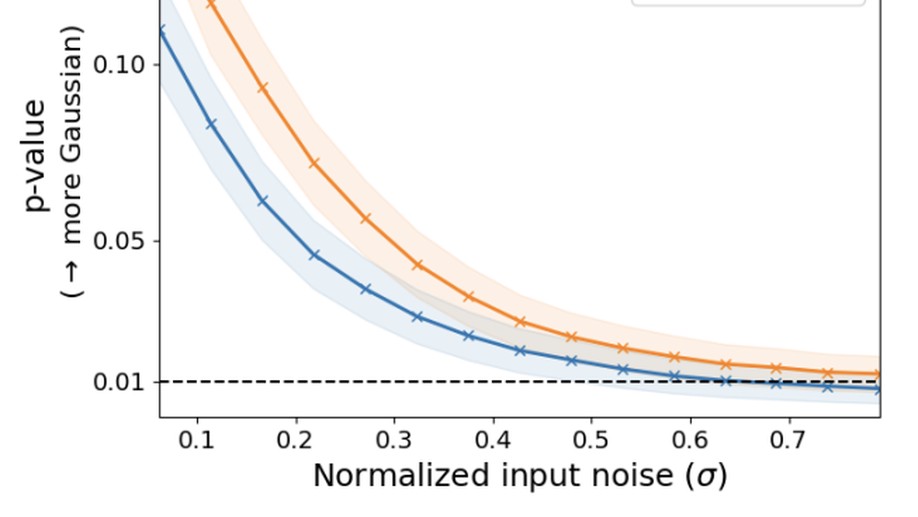
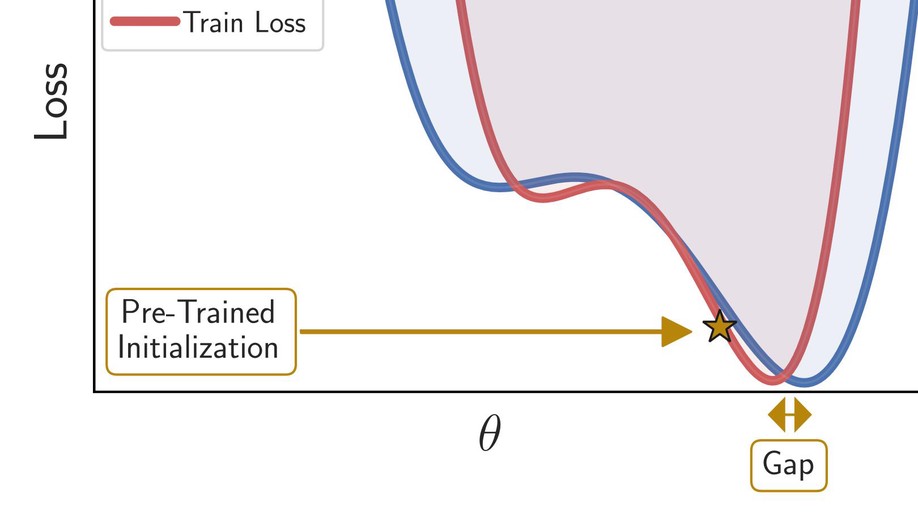
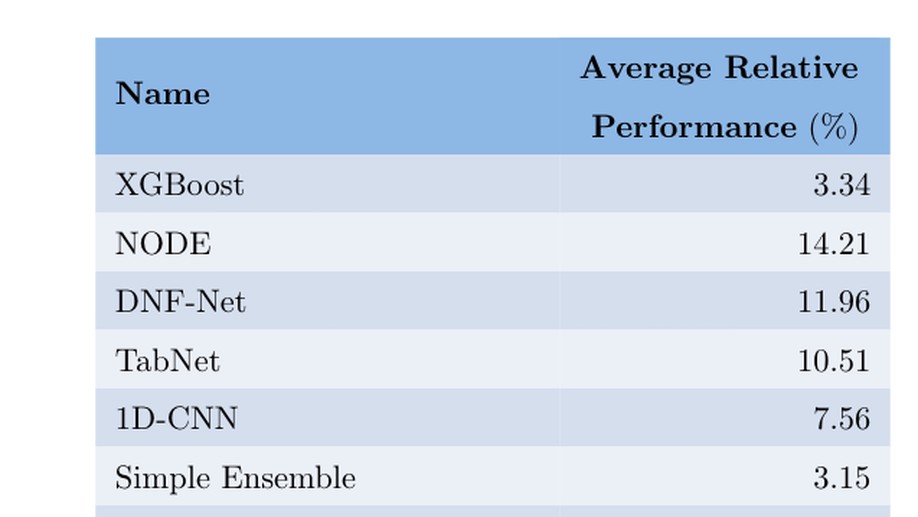
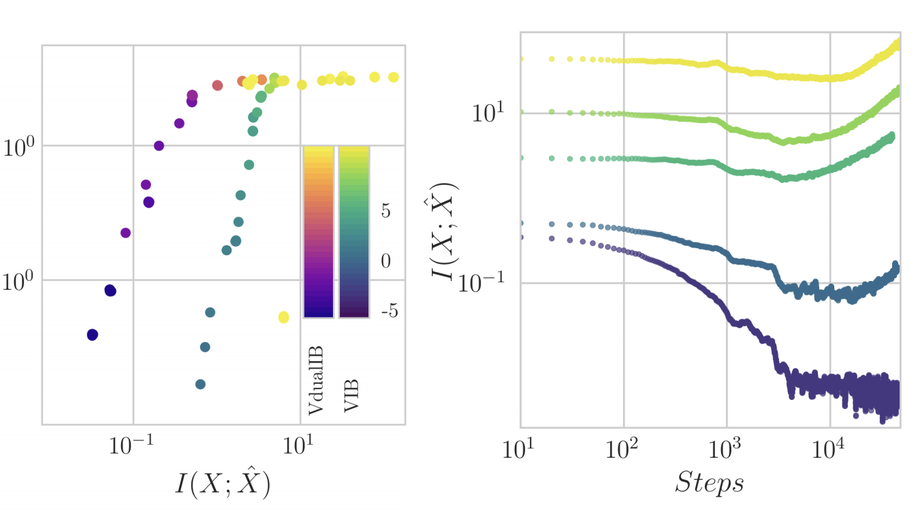
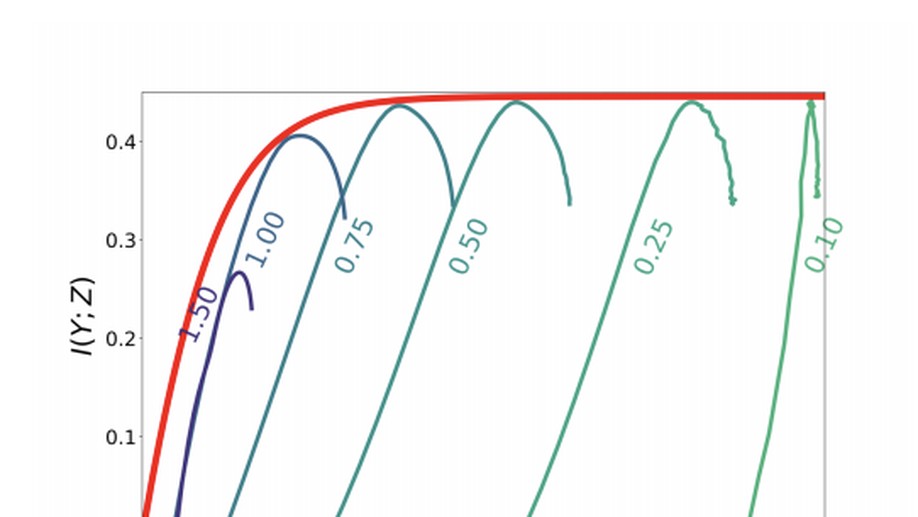
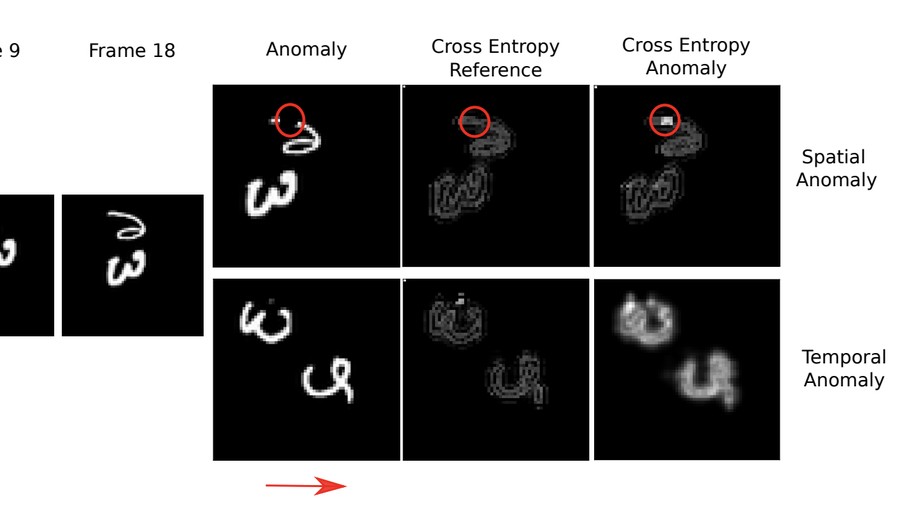
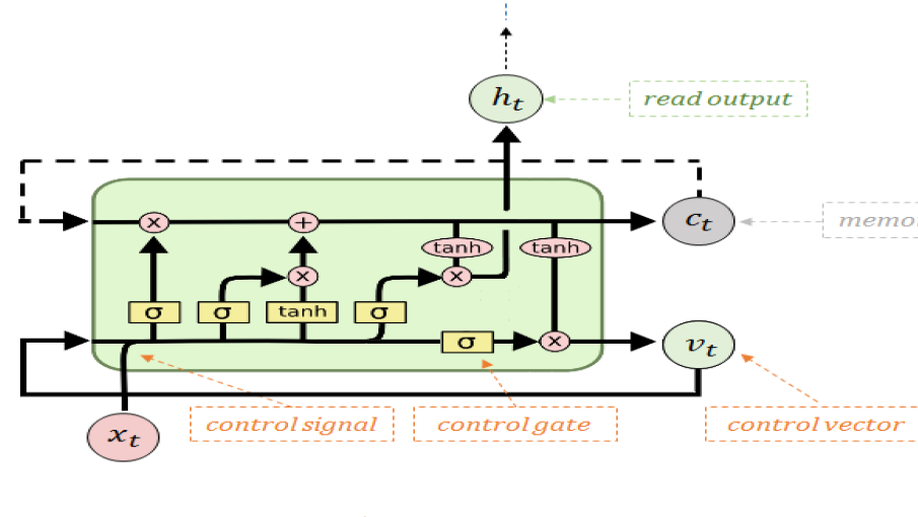
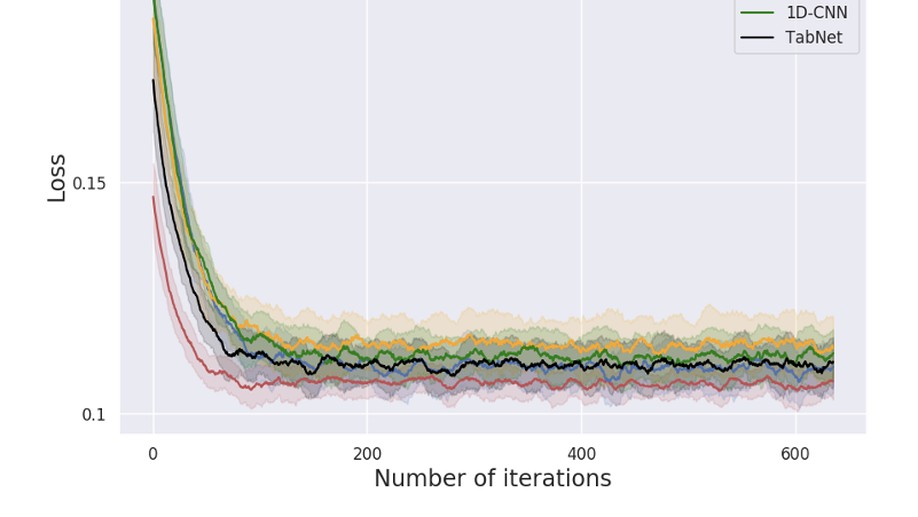
Ravid Shwartz-Ziv
Assistant Professor and Faculty Fellow, Center for Data Science, New York University
Senior Research scientist, Wand AI
Biography
Biography
I am an Assistant Professor and Faculty Fellow at NYU’s Center for Data Science, where I lead cutting-edge research in artificial intelligence, with a particular focus on Large Language Models (LLMs) and their applications. My work spans theoretical foundations and practical implementations, combining academic rigor with industry impact.
Research Focus
My research bridges fundamental theoretical understanding with practical applications in AI, particularly focusing on:
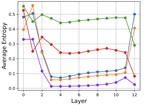
- Pioneering novel approaches for analyzing LLM representations and intermediate layer dynamics
- Developing efficient model adaptation and personalization techniques
- Advancing information-theoretic frameworks for understanding neural networks
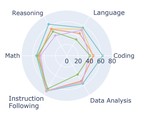
- Creating innovative benchmarking frameworks for evaluation of AI systems
Notable Achievements
- Pioneer in applying information theory to neural networks, with seminal work featured in Quanta Magazine and Wired
- Published extensively in top-tier venues (NeurIPS, ICLR, ICML)
- Google PhD Fellowship recipient (2018-2021)
- Best Paper Award, Information Fusion journal (2023)
- CPAL Rising Star Award, The University of Hong Kong (2023)
- Moore-Sloan Fellowship, NYU (2021-2022)
Current Projects
- Leading research initiatives in LLM personalization and adaptation
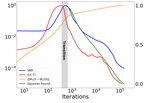
- Developing novel approaches for analyzing and improving model efficiency
- Creating new frameworks for understanding information flow in large-scale models
- Advancing multi-agent systems and user-centric search implementations
My work combines theoretical insights with practical applications, contributing to both the academic understanding of AI systems and their real-world implementation. Through my dual role in academia and industry, I strive to bridge the gap between theoretical breakthroughs and practical applications in AI.
Interests
- Large Language Models (LLMs)
- Model Efficiency & Compression
- Information Theory
- Neural Network Interpretability
- Self-Supervised Learning
- Representation Learning
- Multi-Agent Systems
- Personalization in AI
Education
Ph.D. in Computational Neuroscience, 2021
Hebrew University of Jerusalem
B.Sc. in Computer Science and Computational Biology, 2014
Hebrew University of Jerusalem